As enterprise digitalization continues to deepen, endpoint devices have become the core carriers of day-to-day operations and data circulation. Laptops, desktops, and various office endpoints host critical assets such as source code, design drawings, business documents, and customer information. With remote work, branch collaboration, and hybrid work gradually becoming the norm, endpoints are no longer concentrated within a single office network environment, and the management boundary for endpoints has expanded accordingly.
This shift raises the bar for IT operations in small and midsize businesses. On one hand, IT staff must provide timely support to endpoints across different locations and network conditions to ensure business continuity. On the other hand, endpoint dispersion significantly increases the potential risk of data leakage. If remote operations lack centralized management and activity auditing, organizations will struggle to answer a fundamental question with confidence: “Who, at what time, by what means, performed which actions on which endpoint?”
In practice, data leakage incidents are not always the result of external attacks; they more often occur during routine operations and internal activities. For example, files may be transferred through nonstandard channels during remote assistance, temporary permissions may not be revoked in time, or inconsistent endpoint configurations may cause security policies to fail. These issues are often difficult to detect promptly, yet they can introduce persistent risk.
Against this backdrop, more organizations are rethinking the role of remote tools within endpoint management and Data Loss Prevention (DLP). Remote tools should no longer be treated as simple “emergency troubleshooting” utilities; they should be a controllable part of the endpoint management system—with clearly defined privilege boundaries, complete operational traceability, and auditable administrative controls. How to preserve operational efficiency while ensuring visibility and traceability of remote actions has become an essential challenge for SMBs in endpoint management.
Risk sources: Hidden issues in everyday work and IT operations
In distributed work environments, endpoint risks rarely erupt in a single concentrated event. Instead, they tend to exist as fragmented, ongoing issues embedded in everyday work and routine IT operations. In high-frequency scenarios such as remote support, file handling, and endpoint configuration, risks will gradually accumulate and amplify if there are no unified standards and technical constraints.
First, the diversity of endpoint network environments makes traditional management models centered on an “internal network perimeter” difficult to apply. Employees may use endpoints from different locations and network conditions, and IT staff may need to provide support across networks. In such cases, if remote access channels are not centrally managed, it becomes difficult to effectively control access sources, connection methods, and operational scope.
Second, if the large volume of actions generated during remote operations is not systematically recorded, an organization’s audit capability is directly weakened. Actions such as remote desktop control, file transfers, and configuration changes—without sufficient logs—are hard to reconstruct after the fact and cannot provide reliable evidence for internal audits or compliance checks.
In addition, as business systems and workplace tools continue to expand, file circulation paths become increasingly complex. Files may move between endpoints through remote assistance tools, instant messaging, or temporary storage methods. If these paths are not included in unified governance, DLP policies will struggle to cover real-world usage scenarios comprehensively.
● Endpoints are distributed across diverse network environments, with complex access paths
● Remote operations lack a unified entry point and audit mechanism
● File transfer methods are diverse, making unified constraints and logging difficult
● Compliance and customer requirements demand higher standards for operational traceability
Practical challenges: Why it’s “important, but hard to implement”
Although most organizations recognize the importance of endpoint management and audit trails, implementation often encounters real-world execution challenges. These are rarely a single technical problem; they are usually caused by a combination of management complexity, staffing costs, and tool fragmentation.
On one side, remote tools and endpoint management tools have long been disconnected. Remote assistance often relies on standalone tools with limited linkage to endpoint assets, user identities, and policy configurations. This disconnect makes it difficult to incorporate operational behavior into a unified management system, increasing uncertainty caused by manual actions.
On the other side, operational efficiency and security auditing are often seen as conflicting goals. Some organizations worry that introducing audit and control mechanisms will add steps and slow down response times. As a result, “quick resolution” tends to be prioritized in practice, while recordability and traceability of actions are overlooked.
Additionally, SMBs typically face limited IT headcount. Manual configuration, manual record-keeping, and cross-tool collaboration increase operational burden and raise the likelihood of errors. As the number of endpoints and business complexity grow, this approach becomes unsustainable.
● Tools are fragmented, lacking unified management and policy linkage
● Hard to balance audit requirements with operational efficiency
● Endpoint status is not visible enough, leading to delayed issue detection
● Heavy reliance on manual actions increases configuration drift
● Operations processes lack standardization, making knowledge hard to reuse
Ping32’s approach: Auditable remote endpoint management centered on the Operations Center
Ping32 brings remote capabilities into a unified Operations Center framework. Through coordination of tickets, tasks, and policies, it builds an executable and traceable endpoint operations workflow. The goal is not to increase operational overhead, but to preserve efficiency while ensuring that critical actions follow clear processes and leave auditable evidence.
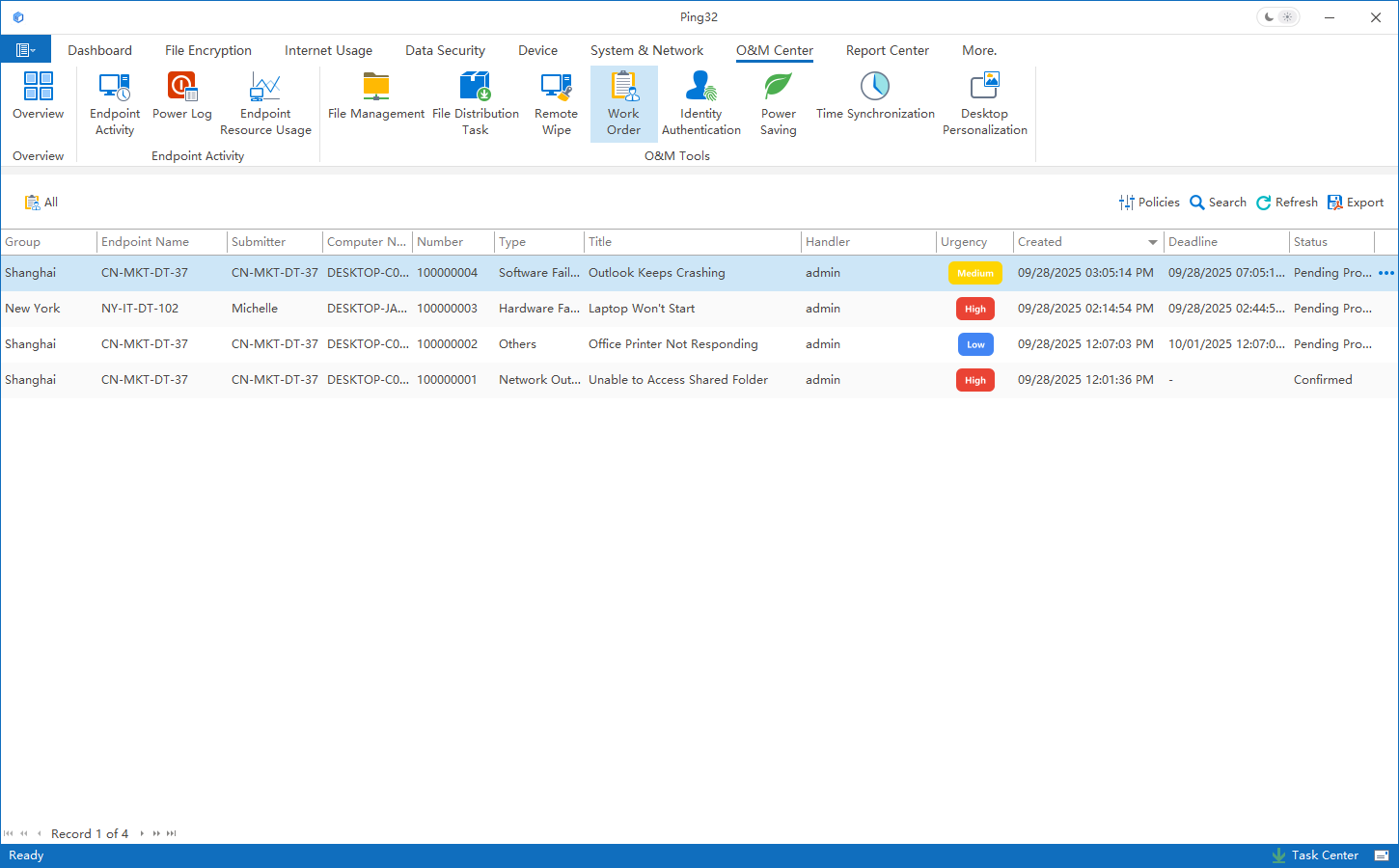
For everyday support, Ping32 structures incident handling through an operations ticket mechanism:
● When endpoint users encounter issues, they submit tickets through a unified entry point. Based on predefined rules or manual triage, the system assigns tickets to the appropriate IT staff.
● After accepting a ticket, IT staff can initiate a remote session directly from the Operations Center to diagnose and resolve the issue on the user’s endpoint.
● After the issue is resolved, IT staff mark the ticket as “Resolved,” and the endpoint user confirms the outcome—forming a complete closed-loop workflow.
Throughout this process, ticket routing, remote sessions, and resolution results are recorded and automatically produce operations logs, providing evidence for later audits and post-incident reviews.
For batch operations, Ping32 provides task distribution capabilities in the Operations Center to centrally execute system optimization, patch updates, and software installation:
● IT staff can configure task policies centrally and deploy them to designated endpoints with one click, reducing configuration variance caused by “non-technical” users. This improves execution consistency and significantly reduces manual intervention time.
● In file management scenarios, task distribution can also be used to deliver notices or business materials to endpoints in a controlled way, ensuring that file delivery paths are clear and governed.
For endpoint lifecycle management, Ping32 includes remote wipe capabilities for scenarios such as staff turnover or device replacement. IT staff can perform data erasure or system reset without physical access to the device. This helps reduce residual data risk during device transfer while improving the efficiency of IT handling.
In addition, Ping32 consolidates multiple foundational operations capabilities into the Operations Center. For example, desktop personalization can be used to standardize wallpapers or lock screens across endpoints, meeting unified management needs or time-based requirements. Time synchronization keeps endpoint system time aligned with the server, reducing logging and audit issues caused by time drift. Power on/off logs and energy-saving settings help organizations plan device runtime while optimizing energy usage without compromising business needs.
Through these capabilities, Ping32 centralizes remote sessions, batch tasks, and foundational management into a single platform—shifting endpoint operations from “ad-hoc handling” to “process-driven management.” This improves efficiency while ensuring that critical actions are auditable and traceable.
Implementation path: A gradual rollout from visibility to policy control
With remote tools built into Ping32, the real question is not whether remote capability exists, but how to build standardized operations processes within the same platform and align them with endpoint security management and DLP policies. For this objective, a phased rollout is more practical.
Phase 1: Standardize on the platform’s remote capability to establish baseline visibility
In the initial phase, organizations can unify the operational entry point by requiring all remote support and endpoint interventions to be performed through the Ping32 Operations Center. Tickets standardize issue intake and reduce reliance on personal habits or ad-hoc methods. The focus is to establish baseline visibility: the target endpoint, the operator, and the time.
Phase 2: Enable audit trails to form standardized operations records
After remote operations are fully brought into the platform, organizations can enable and refine operations logs and activity trails. By continuously recording ticket flow, remote connections, and key actions, they gradually build a complete operations audit chain. The primary value is traceability that supports internal audits, post-incident analysis, and compliance needs.
Phase 3: Use tasks and policies to improve execution consistency
As endpoint scale and operational complexity increase, organizations can leverage task distribution to shift routine work from “manual per-device handling” to “centralized policy execution.” System updates, patch deployment, software installation, and file delivery can all be centrally configured and executed by policy, reducing the management impact of endpoint environment differences.
Phase 4: Integrate operational behavior into security and DLP governance
Once operations processes stabilize, organizations can further link remote operations with endpoint security and DLP policies. For example, restrict the scope of permissible remote actions based on endpoint status, user role, or business context. In this way, operations are no longer independent actions but become a governed part of the endpoint security management system.
By advancing through these phases within a single platform, organizations can steadily improve operational standardization and control without introducing additional tool complexity. Ping32’s remote capability, Operations Center, and security policies can then work together in a sustainable, long-term operating model.
Summary: A practical and sustainable way to run endpoint operations
As endpoint counts continue to grow and work models evolve, organizations must raise both operational efficiency and data security at the same time. Ping32 does not treat remote tools as standalone functionality; it embeds them into an integrated platform spanning endpoint security management, DLP, and the Operations Center, allowing remote actions to naturally fit into everyday operations.
With a unified entry point, process-based tickets, centralized task execution, and comprehensive activity logging, organizations can progressively build a clear and traceable endpoint operations system. This approach emphasizes standardizing operations behavior rather than over-restricting staff, helping maintain business continuity while improving management transparency.
More importantly, the system can evolve sustainably. Organizations can phase in deeper auditing and more granular policies based on their scale, business cadence, and compliance requirements—without frequently changing tools or operating models. When remote tools, operations workflows, and security policies run together within the same platform, the costs of fragmented management are reduced.
In practice, Ping32 provides an “executable” and “verifiable” management approach—shifting endpoint operations from reactive response to long-term controllability and helping organizations build a stable, sustainable foundation for endpoint management.
FAQ
-
Does Ping32’s remote tool support auditable activity logging?
Yes. Remote connections, operational processes, and related actions can be recorded for subsequent audits and analysis.
-
Is the remote tool only for troubleshooting?
No. In addition to remote assistance, it can also be used for file distribution, configuration management, and endpoint status checks.
-
Do we need to deploy additional third-party software to use Ping32’s remote tool?
No. Remote capability is integrated into Ping32’s endpoint management system and is deployed and managed centrally.
-
Can remote file transfers be brought under DLP governance?
Yes. File transfer activity can be managed in combination with DLP policies and audit mechanisms.
-
Is Ping32’s remote tool suitable for small IT teams?
Yes. One of its design goals is to reduce daily operations complexity and minimize manual workload.


 Contact
Contact


































 12 min
12 min 





