多くの企業で、端末データの損失は必ずしも攻撃や誤削除だけが原因ではありません。より基本的な問題、つまりディスクが徐々に劣化しているのに誰も早く気づけないことが原因になる場合も多くあります。財務資料が突然開けなくなる、設計ファイルが SSD 書き込み異常で壊れる、カスタマーサポート端末が断続的に重くなった後に停止する、開発端末の不良セクタ増加が見落とされる。この種の問題は本当に「突然」起きるというより、故障の兆候が一定期間積み上がった結果として表面化することが多いのです。
危険なのは、ディスクの健康問題が最初から完全故障として現れるわけではないことです。多くの端末では、実際の故障前に寿命劣化、温度異常、読み書きエラーの増加、不良セクタの発生といった兆候が現れます。IT チームが社員の申告を待ってから調べるだけでは、データ保護は結局、事後対応のままです。企業にとってディスク健康状態は、故障修理担当者がたまに見る技術情報ではなく、日常運用の巡回指標として扱われるべきです。
なぜ企業は端末ディスクの健康状態を継続的に確認すべきなのか
HDD や SSD の故障は、単に一台の PC が不調になるだけで終わりません。データ完全性、システム安定性、業務継続性に直接影響します。特に財務、開発、設計、サポートなど、ローカルデータと端末の安定性への依存度が高い部門では、ディスク障害は単なるハードウェア交換では済みません。文書破損、データ損失、納期遅延、緊急復旧コストの増大につながります。
さらに、端末数が増えるとディスク状態の確認は手作業で一台ずつ行うには向かなくなります。企業に統一された確認入口がなければ、どの端末のリスクが高まっているのか、どの機種を優先的に更新すべきか、どの端末がまだ動いていても実は故障寸前なのかを判断しにくくなります。ディスク障害によるデータ損失を防ぐとは、壊れた後に復旧することではなく、壊れる前に兆候を見つけることです。
重要なのは一度確認することではなく、日常運用の判断軸に組み込むこと
多くの企業では、ディスク健康確認はいまだに「問題が起きたら診断する」という考え方に偏っています。しかし運用の観点から見れば、ディスク健康度は端末ストレージの健康診断レポートに近いものです。完全に壊れた後に「壊れています」と言うためのものではなく、状態悪化の前に判断材料を示すためのものです。これを日常運用へ組み込んで初めて、端末ハードウェア管理は受け身の障害対応から、予防保守へ進みます。
実用的な方法は大きく三つあります。第一に、IT が端末の健康度を一元的に確認できる入口を持つこと。第二に、健康度の低下を見た時点でバックアップ、点検、交換の計画へつなげること。第三に、健康度を単独数値として扱わず、使用年数、故障履歴、業務重要度と合わせて判断することです。そうすることで、健康度確認が本当にデータ損失防止へつながります。
Ping32 で HDD / SSD の健康状態をどう確認するか
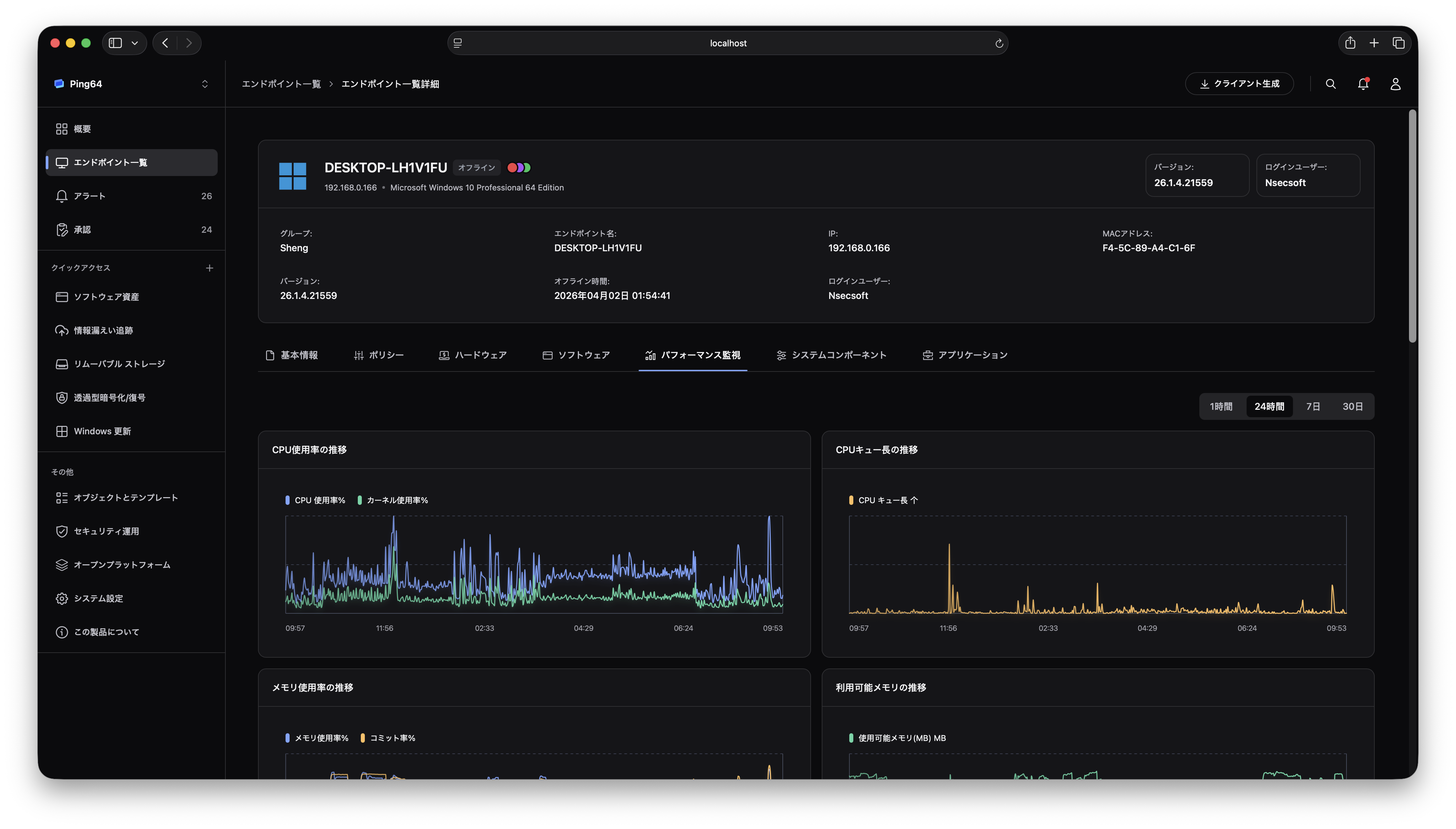
1. ハードウェア資産で端末のディスク健康度を一元的に確認する
管理者は Ping32 コントロール台で デバイス管理 -> ハードウェア資産 -> ハードディスク -> 健康度 の順に進み、端末ディスクの健康状態を確認できます。手冊では、Ping32 の ディスク健康度 機能は運用担当者が事前にディスク故障リスクを把握するためのものと説明されています。この入口の価値は、個々の端末に散在していたストレージ状態を統一された資産・運用ビューへ戻す点にあります。
端末数が多く、使用年数もばらつく企業環境では、これは特に重要です。管理者は社員から「PC が重い」「ファイルが開けない」と報告されるのを待つ必要がなくなり、どの端末で健康度の異常や低下が起きているかを先に把握できます。
2. 健康度が意味するリスク信号を理解する
手冊によれば、ディスク健康度は「そのディスクがまだ正常に動作できるか」を示す総合指標であり、通常は S.M.A.R.T. データを基に評価されます。対象には、通電時間、温度異常、不良セクタ数、読み書きエラー回数、寿命摩耗、故障予兆などが含まれます。
つまり、管理者は健康度を単なる抽象的な数値として見るべきではなく、故障リスクの集約信号として理解すべきです。HDD では不良セクタや I/O エラーの変化が重要になりやすく、SSD では寿命消耗や書き込み劣化が重要になりやすい。いずれにしても、健康度の意味は「故障リスクが存在するか、データ損失につながり得るか」を先に知らせることです。
3. 健康度が異常、または継続的に低下している端末には早めにバックアップと交換計画を立てる
手冊の利用提案では、健康度が異常、または継続的に低下している端末については、速やかにデータバックアップ、ディスク点検、交換計画を進めるべきだとされています。これは「起動しなくなった」「ファイルが壊れた」という報告が出てから始めるべき作業ではありません。成熟した運用では、健康度異常そのものを予兆として扱います。
特に財務、開発、設計、サポートなどローカルデータの価値が高い端末では優先度を上げるべきです。なぜなら、こうした端末でディスク障害が起きると、単なる部品交換費用ではなく、文書復旧コスト、業務停止時間、納品リスクまで発生するからです。
4. 健康度は使用年数や故障報告履歴と合わせて判断する
Ping32 の手冊では、健康度 は使用年数や故障報修記録と合わせて参照すべきであり、単一指標だけで判断してはいけないとも述べられています。つまり、管理者はある一つの健康度状態を機械的に「即交換」や「問題なし」と決めつけるべきではありません。端末の所属業務、使用時間、最近の異常、修理履歴を合わせて判断する必要があります。
この考え方は二つの極端を避けるために重要です。一つは、まだ安定運用可能な機器を過剰に交換してしまうこと。もう一つは、明らかに劣化が進んでいるディスクを楽観視し、重要業務で使い続けてしまうことです。健康度が提供するのは結論そのものではなく、適切な判断の材料です。
5. ディスク健康巡回をハードウェア資産管理と予防保守の中へ組み込む
企業にとって、ディスク健康確認は思い出したときだけ見る作業であってはいけません。より安定した方法は、デバイス管理 -> ハードウェア資産 -> ハードディスク -> 健康度 を定期巡回の一部とし、使用年数、故障履歴、資産ロット、交換計画と一緒に管理することです。手冊でも、特定機種に健康度問題が集中する場合は、調達ロットや利用環境も含めて調査すべきだと示されています。
これは、ディスク健康度が単なる一台の診断ツールではなく、ハードウェア運用と資産管理の判断材料にもなることを意味します。企業が本当に防ぐべきなのは一台の突然死だけではなく、同種の問題が複数端末で同時に起きる状況に無防備でいることです。
Ping32 の価値
Ping32 が提供する価値は、単にハードディスクの詳細値を見せることではありません。ディスク健康状態を統一された端末運用ビューへ組み込み、故障リスクを早期に発見し、健康度の異常端末をバックアップ、点検、交換計画へ早くつなげられる点にあります。これによって、本来なら障害後にしか対応できなかったデータ損失問題を、より前の段階で防げるようになります。
端末数が多く、部門ごとの利用形態が異なり、機器ライフサイクルも複雑な企業では、この差は大きいものです。健康度が日常運用に入ることで、HDD や SSD の管理は「壊れたら修理」から「兆候を見て先に動く」へ変わります。その能力そのものが、ディスク障害によるデータ損失を防ぐ鍵です。
FAQ
Q1:なぜディスク健康確認は社員の申告後では遅いのですか。
多くのディスク障害は瞬間的に発生するのではなく、その前に温度異常、不良セクタ増加、読み書きエラー増加、寿命低下などの兆候があります。社員がはっきり異常を感じる時点では、すでにより深刻な段階へ進んでいることが少なくありません。
Q2:Ping32 ではどこからディスク健康状態を見られますか。
コントロール台で デバイス管理 -> ハードウェア資産 -> ハードディスク -> 健康度 に進むことで確認できます。この入口により、端末の HDD や SSD の健康度を一元的に把握できます。
Q3:健康度異常が出たら必ずすぐ交換すべきですか。
必ずしもそうではありません。使用年数、故障履歴、業務重要度、健康度の変化傾向と合わせて判断するべきです。ただし、健康度異常や継続低下が見られる端末については、少なくとも早めのバックアップと追加点検を行うべきです。


 お問い合わせ
お問い合わせ 400-098-7607
400-098-7607 お問い合わせ
お問い合わせ 試用します
試用します


































 4 min
4 min 





