在企业数字化转型不断深化的今天,数据已成为驱动业务增长的核心资产。随之而来的,是更加复杂、更加隐蔽的数据泄露风险。传统安全防护体系(如 DLP)更多聚焦于事前策略与事中阻断,但在“零信任”理念普及、攻击面持续扩大的背景下,泄密事件很难做到 100% 避免。于是,“事后如何高效、精准、完整地溯源取证”,成为企业安全运营与合规审计的关键挑战。
Ping32 提出的聚合搜索(Aggregated Search),是一套面向安全事件响应阶段(Incident Response)的创新能力体系:它不只是“更快的日志检索”,而是通过重构审计逻辑,将分散、异构的审计数据转化为可验证、可复盘的事件叙事,帮助企业从线索出发快速还原泄密全貌,形成完整证据链。
一、从应急响应的挑战开始:海量日志中的“信噪比”困境
在企业级终端安全审计环境中,单台终端每天可能产生数百条操作日志;在中大型组织内,日均审计数据可达到千万甚至亿级规模。安全事件发生后,安全运营团队面临的核心难题往往不是“有没有日志”,而是典型的信噪比困境:如何在极短的平均响应时间(MTTR)内,从海量、异构数据中快速提取与泄密相关的关键“信号”。
传统审计追溯流程,常常要求管理员在短时间内完成以下任务,但每一步都容易成为效率与准确性的瓶颈:
| 任务目标 |
传统审计的局限性 |
| 时间定位 |
依赖日志时间戳,需跨多个系统人工对齐与比对 |
| 信息识别 |
多基于文件名、主题等元数据做模糊匹配,命中不稳定 |
| 路径还原 |
缺少自动关联机制,需人工串联分散日志 |
| 责任确认 |
证据链易断裂,难形成可用于合规/法律的完整取证材料 |
当日志规模上升到千万/亿级后,基于传统关系型数据库或平面文件的检索方式,查询效率与可用性会快速下降,难以满足现代安全事件应急处置对“快、准、全”的要求。
二、传统审计方案的根本性缺陷:元数据依赖与性能瓶颈
传统审计方案的困境,本质可归结为两类根缺陷:性能瓶颈与取证可靠性不足。
1)性能瓶颈:从关系型检索到全文索引的代际差异
多数传统审计工具的“搜索”,本质是在底层数据库中对元数据字段(如文件名、路径、收件人、主题等)进行查询。数据量小时尚可接受,但在千万级、亿级规模下,查询成本会显著上升,响应时间难以保障。
Ping32 聚合搜索的核心技术之一,是采用分布式全文索引架构(例如基于 Elasticsearch 的倒排索引思路),通过对全量审计数据预先建立索引,将查询从“扫库式查询”转为“索引式命中”,在大规模数据与高并发场景下保持稳定的检索体验。这类性能差异,是安全事件响应“跑得动”的前提。
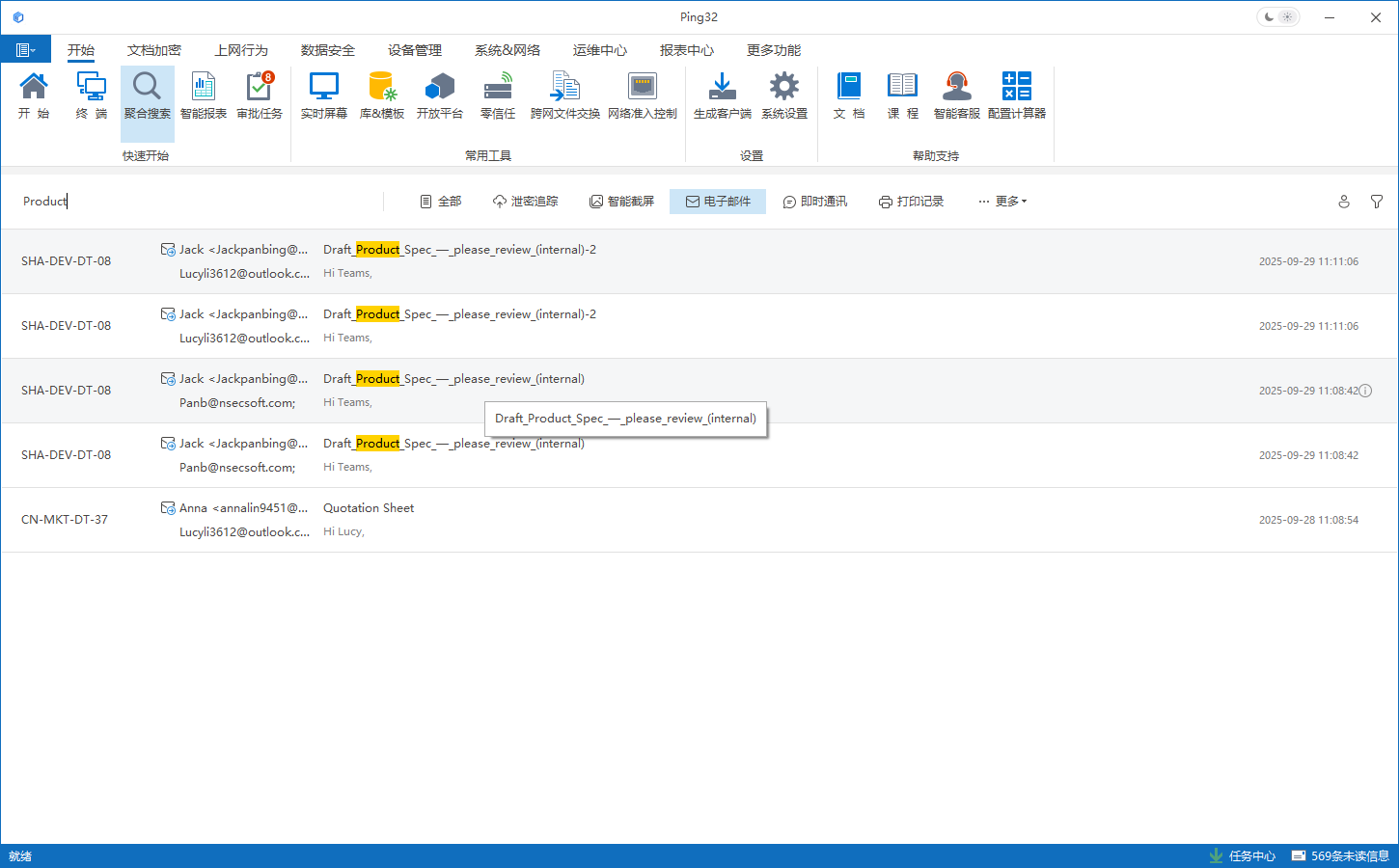
2)取证可靠性:文件名并不是可靠的溯源依据
更深层的问题在于取证可靠性。传统方案高度依赖文件名、标题、路径等元数据进行追溯,但在真实泄密场景中,元数据天然脆弱且易被对抗:
因此,基于元数据的审计结果往往是“概率命中”,而非“必然可追溯”。一旦元数据被破坏或伪造,审计链条就可能断裂,难以支撑合规审计与法律取证。
在 Ping32 的设计中,元数据检索更适合作为“事件分诊/初筛能力”,但无法作为最终溯源与取证的核心。
三、聚合搜索的核心价值:从“元数据”到“内容级深度匹配”
聚合搜索的关键突破在于内容感知:把关注点从“文件叫什么”转向“内容是什么”。
1)应对碎片化线索:从“文件”到“片段”的搜索逻辑
实际泄密事件中,管理员往往拿不到完整源文件,而只掌握一些碎片线索,例如:
-
一段敏感业务数据片段
-
一个手机号码、身份证号、客户编号
-
一句内部项目代号、关键术语
-
一小段截图文字或 PDF 片段
这些线索通常无法直接映射到日志字段,更难通过文件名或主题准确命中。
2)内容级聚合搜索如何实现
Ping32 聚合搜索通过以下机制实现内容级深度匹配与跨域定位:
-
全量内容索引:在采集阶段,对文件内容、邮件正文、IM 消息等数据载荷进行文本提取,建立全文索引
-
事后按需搜索:无需提前配置复杂规则或正则,事件发生后可直接输入任意线索(片段、号码、关键词等)
-
极速匹配与自动聚合:在全量索引中快速命中,并自动聚合所有包含该内容的跨类型行为记录
只要敏感内容曾被记录或流转,哪怕被改名、拆分、重复拷贝,仍可通过内容级匹配精准定位。
四、聚合搜索的高级能力:视觉智能与关联分析,消除审计盲区
要实现真正的“无死角”审计,仅有文本索引还不够。聚合搜索进一步融合视觉智能与关联分析,覆盖更多对抗场景。
1)视觉智能:OCR 与以图识图的深度融合
企业中大量敏感信息以非结构化形式存在,如扫描件、图片、PDF、屏幕截图。传统审计系统面对这类文件往往等同于“黑盒”,无法检索其内容。
Ping32 将视觉智能深度集成到采集与索引流程,形成两类能力:
通过这一机制,即便泄密者采用“截图外发”“打印-扫描”等方式规避传统检测,管理员仍可通过图片文字内容或视觉特征实现追溯,覆盖更完整的数据形态。
2)事件聚合:基于数据溯源图的关联分析
“聚合”的本质区别在于:传统搜索返回的是孤立日志,聚合搜索返回的是完整事件链。
系统将每一个操作(如创建、复制、压缩、发送、上传)视为图中的节点,将数据流转关系视为边。当一次内容搜索命中初始节点后,系统可沿着关联模型自动扩展并关联多种异构行为:
最终,管理员可通过一次搜索获得可视化“数据流转图谱”,直观还原泄密事件从敏感信息产生到传播再到外泄的全过程,大幅提升溯源效率与证据可信度。
五、结语:聚合搜索,定义新一代安全审计范式
聚合搜索不是简单的“更快搜索框”,而代表着安全审计范式的转型:从“基于日志的被动检索”,走向“基于内容的事件主动还原”。
它直击企业安全运营的三大核心痛点:
-
效率:基于全文索引,在大规模数据下仍保持毫秒级/秒级响应,满足应急响应实时性
-
准确:基于内容级深度匹配,摆脱易变元数据依赖,碎片化线索也能精准定位
-
完整:融合视觉智能与图关联分析,消除非结构化数据盲区,聚合行为为完整事件链,支撑全景溯源与取证闭环
当安全审计不再依赖“概率命中”,当搜索结果能够直接还原“事件真相”,企业的数据防泄漏体系才真正具备可控、可信、可追溯的能力。
FAQ(聚合搜索与安全审计溯源)
1)聚合搜索和传统日志检索最大的区别是什么?
传统检索更像“按字段查记录”,多依赖文件名、路径、主题等元数据;聚合搜索以“内容”为核心,把分散日志自动关联为事件链条,输出可复盘的完整溯源路径,更适合应急响应与取证。
2)聚合搜索是否等同于 Elasticsearch?
不是。Elasticsearch/全文索引是实现高性能检索的重要技术基础之一,但聚合搜索更强调“内容提取 + 多源数据统一索引 + 自动关联聚合 + 事件图谱还原”的整体能力体系。
3)如果我只有一段文字线索或一个手机号,也能查到相关外发行为吗?
可以。聚合搜索支持“碎片化线索”检索,只要该内容曾出现在被采集的数据载荷中(文件内容、邮件正文、IM 消息等),就能通过内容级匹配命中,并聚合关联行为还原传播路径。
4)文件被改名、压缩、加密或换后缀,还能追溯吗?
改名、换后缀不影响内容级匹配;压缩包可在可解析/可提取的情况下进行索引;加密文件若无法解密提取正文,则需结合外发行为、文件指纹/特征、上下游关联等方式进行事件还原(具体取决于采集与解析能力范围)。
5)图片、扫描件、截图里的敏感信息能检索到吗?
可以。通过 OCR,图片/扫描件中的文字可被识别并纳入全文索引;通过以图识图,相似图片也能被检索,适用于裁剪、模糊、重编码等 OCR 难点场景。
6)聚合搜索能把哪些外发通道关联成完整事件?
通常可关联文件操作、邮件、即时通讯(IM)、云盘同步、外设(U 盘)等多通道行为,并支持跨时间与跨对象(用户/终端/接收方)关联,形成“数据流转图谱”。
7)聚合搜索适合哪些团队或场景?
适合 SOC/安全运营、内审与合规、数据安全与 DLP 团队,尤其适用于泄密事件调查、合规审计取证、重大安全事件复盘、跨系统多通道外发溯源等场景。


 在线咨询
在线咨询 400-098-7607
400-098-7607 在线咨询
在线咨询 申请试用
申请试用












 关于安在
关于安在
 新闻动态
新闻动态
 品牌标志
品牌标志
 联系我们
联系我们
 工作机会
工作机会
























 12 min
12 min 
